Product decisions and the data you need, no more no less.

As PMs we are constantly making choices. Every single year, quarter and sprint we need to decide what to do next and where to direct our teams.
For every decision there is a universe of possible things we could choose to do, some of which makes any sense to do, and something that would objectively be the best thing to do. Being the PM is a lot about navigating this universe, narrowing down the choices, and being able to tell a convincing story about why we chose the path we did - especially if we want people to go along with us.
We already know that you learn new things with every product change, and the path to success is iteration, not a flawless first attempt. We want to invest just enough time in learning, to consistently make reasonable choices. We don’t want to get lost in the hunt for the white whale - the objectively best choice. Unless you’re incredibly lucky, a series of reasonable steps are going to take you further than one perfect first step.

The way we tackle this problem is to learn about the universe we’re in. In our case as PMs: the market we operate in, the problem we’re solving, the users we’re solving for, and the state of our product as it already is.
To be able to learn though, we need information. We need data. Getting this data, and going from having data to learning from the data is a rabbit hole that can be incredibly time consuming and often have steeply diminishing returns. So how do we avoid the rabbit hole? How do we know when to stop digging, learn what we can, and make a decision with what we know?
Fundamentally Data plays two roles in a product cycle. You use it at the beginning to identify opportunities and you use it at the end to evaluate if you managed to capture the opportunity.
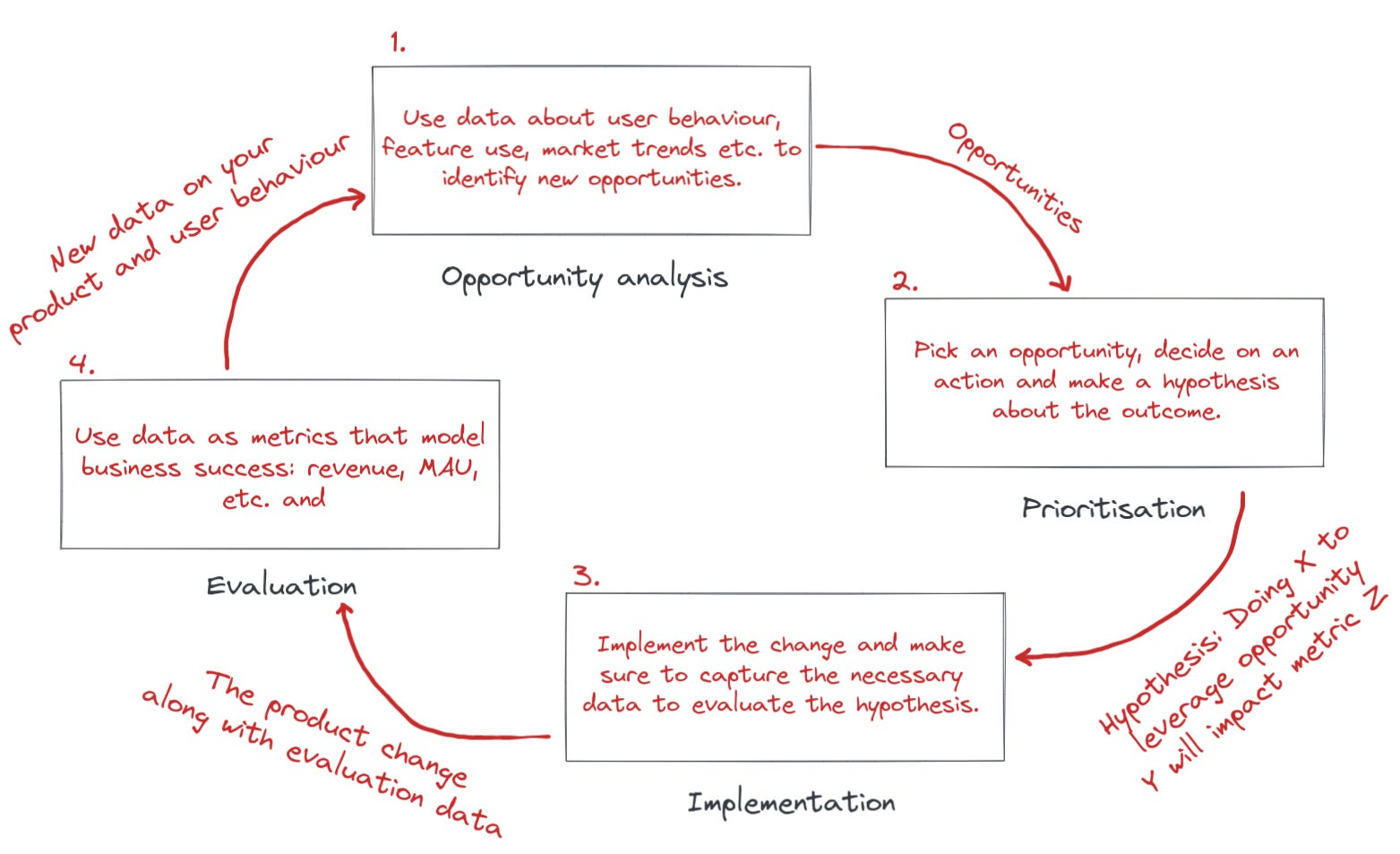
Usually the data supporting the two cases is roughly the same. In the opportunity analysis you look at it in an ad hoc way, you turn it around, dig deep, look from many angles to learn the little intricacies. In the evaluation stage you want to remove all such creativity. When evaluating you just want to validate your hypothesis, the hypothesis that you stated as you started changing the product.
This hypothesis should already have had a metric defined and a rough estimate of how much it should change. If it turns out that your hypothesis didn’t materialize then that’s a learning you bring into the next opportunity analysis. Resist the urge to shift the goal post in evaluation and picking another metric or evaluation criteria - if it didn’t work it didn’t work, you want to learn the right thing for the next opportunity analysis.
So you need data to generate opportunities and hypotheses, and for evaluation. But what data do you need? Big surprise: it depends. More than anything it depends on the maturity of your product. If you’re setting out to leverage your first opportunity or if you’ve been tuning your offering for years.
In the very beginning of the product journey - the opportunities are obvious, and the expected impact of every change is high. You're building the foundation of your product, and if your hypothesis is correct, that should greatly impact your top level metrics. For example: This is where you allow your primary segment access to your value proposition, where you add basic functionality, where you remove the most obvious points of friction.
I like to think about a sequence of opportunities as a tree, where every captured opportunity opens up a new set of opportunities. In each node in this tree, you need the information necessary to form a hypothesis on what change to the product would capture the opportunity. Each opportunity has its own universe of choices and its own set of reasonable approaches. Once you’ve informed yourself about the universes that you have available to you you can evaluate which of your opportunity capturing options is most bang for the buck, and that’s your next step.

As you work through your opportunity tree over time, you rarely close doors behind you. In each node you just chose what to do next, not necessarily what opportunities to abandon forever. So as you progress over time, the set of available opportunities grows. They include the new ones you unlock, and all of the ones you didn’t prioritise earlier. This of course requires that you have more and more data to evaluate which opportunity to go for next.
The flip side of this though is that at the top of the tree, when you make your first choices, you have a limited set of available opportunities, and you can make a choice with way less data. The further up you are in the tree, the more important it is to not get caught up in the data rabbit hole - the opportunity cost is massive.

Knowing that depending on the set of available opportunities we need more or less data, but which kind of data do we need? It all depends on what metric your hypothesis intends to move.
Higher level metrics require massive impact to change enough for you to notice. Your first opportunities will exhaust the changes that can easily be evaluated with high level metrics and you’ll have to rely on more local metrics to see large enough metric changes to evaluate your hypotheses.
In the beginning you’re likely operating on very high level metrics: number of users, revenue, logins etc.
As you go further down the tree you’ll have exhausted the changes you can make that individually, meaningfully, move these top level metrics. Now you need to focus on a more specific metric, something like engagement per user, usage of specific features of your product etc.
Even further down you’re probably iterating on specific variations of your features or personalised functionality. Now you’d need hyperlocal metrics that capture specifically the variation you made, like the click-through-rate of personalised pieces of content depending on position or some recommendation model state.
To be able to form a hypothesis to move any of these metrics you need to capture that data in the first place. As the metrics grows more local and you chase lower magnitude metric shifts, the more advanced your methods need to be to collect, process and analyse.

Be honest about which opportunities are actually in reach from where you stand - and which are for you to tackle in the future. Then gather the data necessary to make an informed choice between the actually available opportunities. Choose the opportunity where your hypothesis predicts the greatest impact with the lowest effort. And then make sure that as you ship new things, you also capture the data you need to evaluate the change and be even better informed in the next round.
Don’t compromise with making informed choices, but don’t waste time chasing the perfect decision. Find and leverage the data you need, no more no less.
If you want to hear us talk this through with more examples and tangents you should check out this episode of the Product Internals podcast!